Merkle Tree, 也叫 Hash Tree. 它是Ralph Merkle在1979年创造的。据说最早Merkle创造Merkle Tree(MT)的目的是为了生成Lamport签名,一种一次性的数字签名.

上图(来自Wikipedia)给出了一个二进制的哈希树(二叉哈希树, 较常用的tiger hash tree也是这个形式). 据称哈希树经常应用在一些分布式系统或者分布式存储中的反熵机制(Anti-entropy),也有称做去熵的.这些应用包括 Amazon的Dynamo 还有Apache的Cassandra数据库, 通过去熵可以去做到各个不同节点的同步, 即保持各个节点的信息都是同步最新.
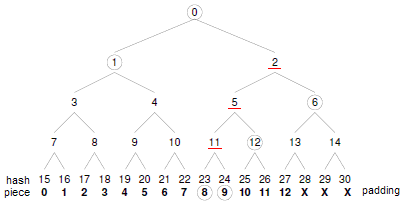
哈希树的特点很鲜明: 叶子节点存储的是数据文件,而非叶子节点存储的是其子节点的哈希值(称为MessageDigest) 这些非叶子节点的Hash被称作路径哈希值, 叶子节点的Hash值是真实数据的Hash值. 因为使用了树形结构, MT的时间复杂度为 O(logn)
比如下图中, 我们如果使用SHA1算法来做校验值, 比如数据块8对应的哈希值是$H23$, 则按照这个路径来看应该有1
2
3
4H11=SHA1(H23∥H24)
H5=SHA1(H11∥H12)
H2=SHA1(H5∥H6)
H0=SHA1(H1∥H2)
其中$\parallel$是表联接的意思.
应用举例
BitTorrent中应用
在BT中, 通常种子文件中包含的信息是Root值, 此外还有文件长度、数据块长等重要信息. 当客户端下载数据块8时,在下载前,它将要求peer提供校验块8所需的全部路径哈希值:H24、H12、H6和H1. 下载完成后, 客户端就会开始校验, 它先计算它已经下载的数据块8的Hash值23, 记做 H23′ , 表示尚未验证. 随后会按照我在上一小节中给出的几个公式, 来依次求解 直到得到H0′ 并与H0做比较, 校验通过则下载无误. 校验通过的这些路径哈希值会被缓存下来, 当一定数量的路径哈希值被缓存之后,后继数据块的校验过程将被极大简化。此时我们可以直接利用校验路径上层次最低的已知路径哈希值来对数据块进行部分校验,而无需每次都校验至根哈希值H0.
Amazon Dynamo中同步
在Dynamo中,每个节点保存一个范围内的key值,不同节点间存在有相互交迭的key值范围。在去熵操作中,考虑的仅仅是某两个节点间共有的key值范围。MT的叶子节点即是这个共有的key值范围内每个key的hash,通过叶子节点的hash自底向上便可以构建出一颗MT。Dynamo首先比对MT根处的hash,如果一致则表示两者完全一致,否则将其子节点交换并继续比较的过程, 知道定位到有差异的数据块. 这种同步方式在分布式中有着节省网络传输量的优点.
引用:
http://en.wikipedia.org/wiki/Hash_tree
http://en.wikipedia.org/wiki/Lamport_signature
http://blog.csdn.net/starxu85/article/details/3859011
http://ultimatearchitecture.net/index.php/2010/09/12/merkle-tree/
http://www.public.asu.edu/~rzhang46/
http://yishanhe.net/wiki/Secure-topk-query.html
http://www.bittorrent.org/beps/bep_0030.html
https://www.usenix.org/conference/osdi12/secure-offline-data-access-using-commodity-trusted-hardware
